Finding structure in Indian-origin English words
Indian-origin words like pyjama, jungle or chutney are part of everyday English.
The other property that these words share is that they are part of the official Scrabble Dictionary (the ~280K words that are "officially" playable in Scrabble).
The Scrabble dictionary is a mishmash of words — some natively belonging to the English language, and some like the ones listed above adapted from other languages. I was curious what kinds of words actually get adapted into the English language, and whether there's any structure to which ones stick.
To find out, I clustered the embeddings of all Indian-origin words in the Scrabble dictionary with an off-the-shelf embedding model, and also finetuned a small embedding model of my own.
Note: The Scrabble Wordlist overlaps with the English dictionary but it is not 1:1. I used this dataset as a proxy for what words end up making it into the English language.
The setup
I started off by separating the ~2,600 Indian-origin words from the ~278,000-word CSW24 dataset. I embedded them with gemini-embedding-001, clustered with HDBSCAN, and asked Gemini to come up with labels for the clusters.
Credit to Joshua Castellano and the Scrabble community for this annotated dataset which includes the origins of CSW words.
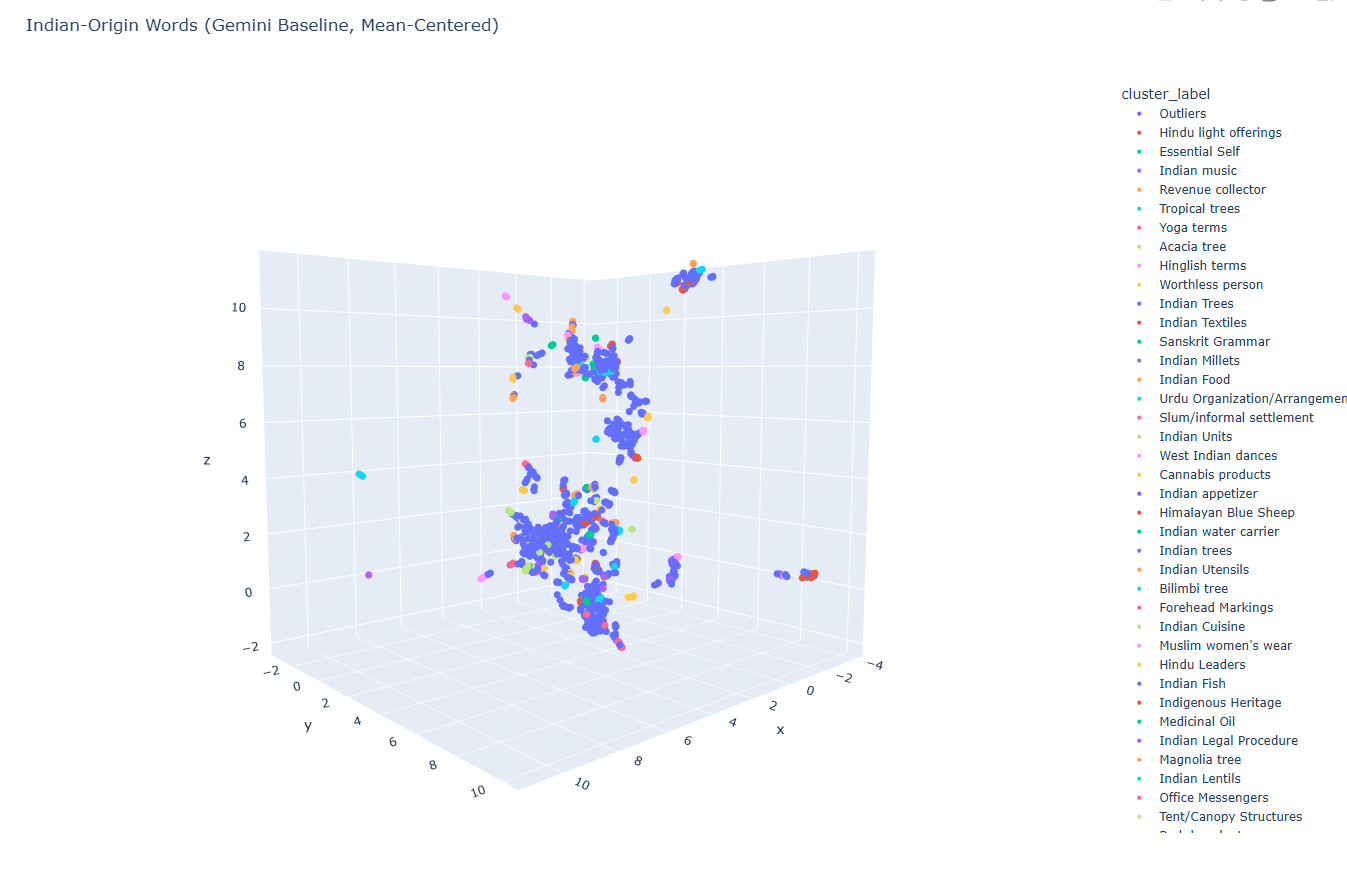
Here's the result. There's some grouping, but honestly I wanted to learn how embedding models are trained — and see if finetuning one made a difference. So I finetuned a small embedding model (all-MiniLM-L6-v2) on the full ~278,000 CSW24 word-definition pairs, holding out Indian-origin words so they wouldn't leak into training. The model is on HuggingFace; details below if you're curious.
Training details
Since the dataset is pairs of (word, definition) there are no "negative" examples for training. However, within each batch of (word, definition) pairs, for each word, you can consider all the other definitions as negative examples. For instance:
| Word | Definition |
|---|---|
| Chameleon | Small reptile |
| Cook | Someone who makes food |
| Crab | Sea animal |
For a particular word, say "cook", you can consider "sea animal" and "small reptile" to be negative examples since they are explicitly not the definition of "cook".
The optimization function, in this case Multiple Negatives Ranking loss, then tries to pull together the matched pair and pushes the rest apart. With a 64-item batch, you get 63 free negatives per example. For dictionary data this works very well — every entry is a clean positive, and the rest of the batch supplies the contrast.
I also threw in Matryoshka Representation Learning for fun — it trains the embedding so the first N dimensions are themselves a usable embedding. A 384-dim vector contains a usable 256-dim vector inside it, so you can truncate at inference time without retraining. Didn't end up mattering for this analysis but it was a neat thing to learn.
On the held-out test set, word→definition retrieval went from ~50% to 68% Accuracy@1.
I then embedded the 2,600 Indian-origin words with the finetuned model and clustered with HDBSCAN to get the following:
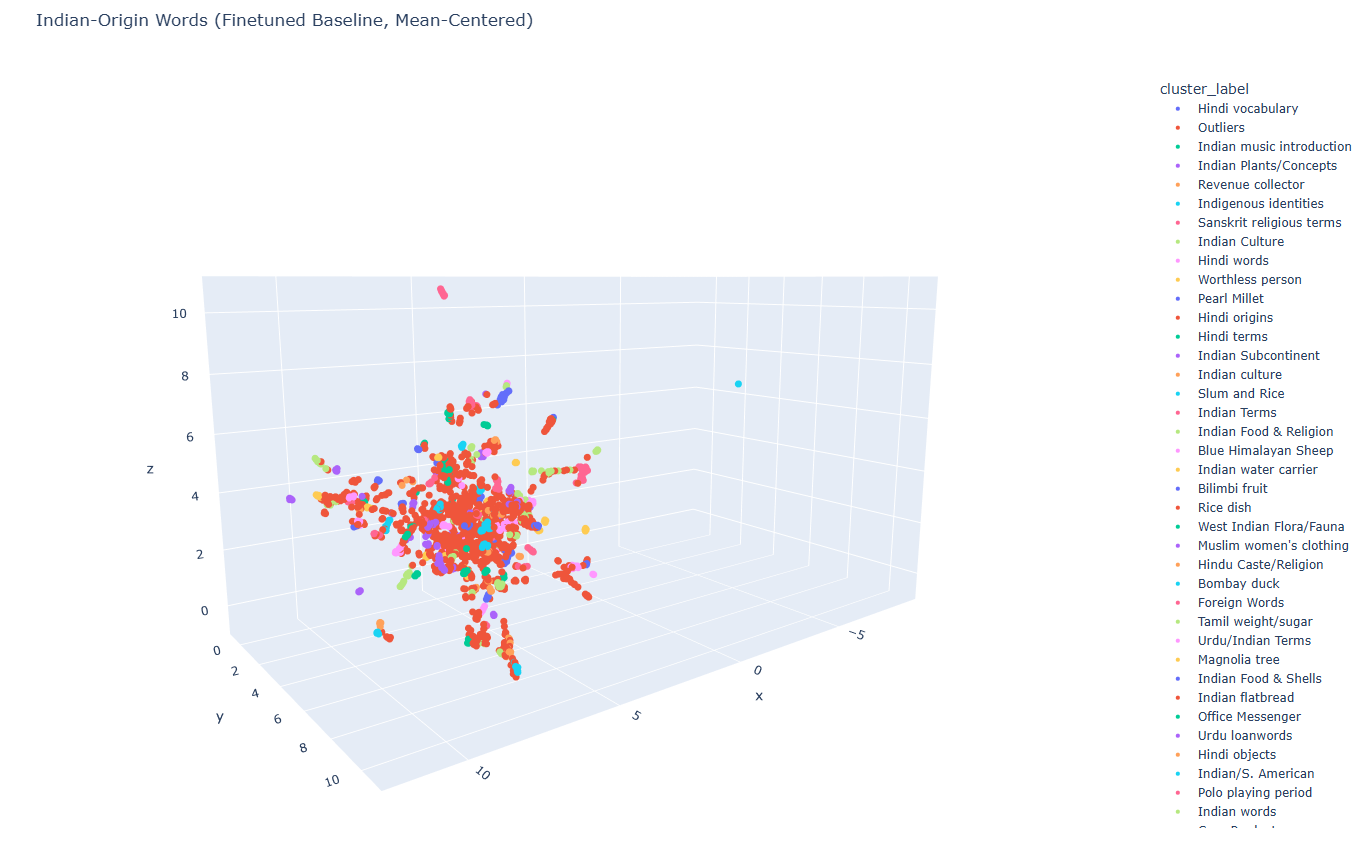
Findings
The words are not random, and pop culture contributed almost nothing. The Indian-origin words English kept are overwhelmingly the ones British administrators, naturalists, and merchants needed vocabulary for in the 18th and 19th centuries. The majority fall under these categories:
- Flora and fauna (~19%) — trees, plants, animals. Includes JUNGLE but also NILGAI (a large Indian antelope).
- Colonial administration (~18%) — land revenue terms, military ranks, legal procedures, titles. Includes THUG but also TALUK (an administrative subdivision) and ZAMINDAR (a landholder who collected revenue for the British). Words English needed because British administrators were running things they had no words for.
- Food and cuisine (~17%) — millets, lentils, breads, utensils. Includes CHUTNEY but also BILIMBI (a sour tropical fruit).
- Religion (~10%) — yoga, mantras, deities. Includes KARMA but also SANNYASI (a Hindu religious mendicant).
- Textiles (~10%) — shawls, turbans, silks. Includes PYJAMA but also JAMDANI (a fine muslin woven in Bengal).
The remaining ~26% breaks into single-concept clusters like "Bombay duck" or "pearl millet", and a long tail of outliers. The words that made it into everyday English are the minority — the Scrabble dictionary, it turns out, is a lexical fossil record.
Conclusion
The next piece of this work is figuring out whether the gain comes from real semantic understanding, or whether the model just learned what dictionary definitions look like.
For now: ZAMINDAR for 78.